C로 배우는 쉬운 자료구조를 참고했습니다.

안녕하세요!!
(순차 자료구조와 연결 자료구조의 차이점을 알고 싶다면?)
(아래 링크 참고해주세요!!)
2021.08.28 - [자료구조] - [C언어] 2차원, 3차원 배열을 통한 순차 자료구조의 사용 예시(테트리스 블록, 휴대폰 판매량, 선형 list)
삽입, 삭제 연산 이후 '연속적' 성질을 유지하기 위해 데이터의 추가 이동을 해주어야 하는 순차 자료와 달리!!
연결 자료구조란?
'동적할당'
필요한 갯수만큼의 (데이터) 노드를 각각 동적 할당 후, 해당 데이터들을 이어주는 방식입니다.
다시 말해서 데이터와 데이터가 연결되어 구현되는 방식이라서,
메모리 사용의 비효율성 문제가 없습니다.
줄줄이 소시지, 또는 화물칸을 실은 기차를 연상할 수 있습니다.

어라?
저 것은 노드인가? 안에 들어있는 것은 아마도
(화물칸을 연결해주는 link와 데이터가 들어있겠군?)

죄송합니다.
연결 자료구조는
데이터와 다음 자료의 주소를 저장 지목하기 위한 포인터를 갖는
Node(노드)를 사용합니다.
한개의 노드에는 <데이터, 주소>//주소: 다음 노드 또는 이전 노드를 가리키기 위해서,,
당연히 한개의 노드에는 여러 개의 자료형이 들어있어서,
구조체를 사용합니다.
연결자료구조를 사용해
여러 개의 노드가 연결되어 있을 때,
아무런 정보가 없다면,
그중에서 가장 첫 번째 노드를 찾기란 정말 쉽지 않습니다.
따라서 첫번째 노드만을 지목하는 head 노드를 사용하는 것입니다.
단순 연결 리스트
단순 연결 리스트는 연결 자료구조의 가장 기본입니다.
(아니,, 처음과 끝이 너무 멀어서 처음의 데이터를 찾고 그다음에 맨 마지막에 있는 데이터를 찾으려면
너무 오래 걸리는 거 아니야?! 젠장..)
이의 단점을 보완한 것이
원형 리스트, 이중 연결 리스트가 대표적입니다.
단순 연결 리스트를 제대로 이해한다면, 원형 리스트, 이중 연결 리스트는
껌입니다.
쉽게 이해할 수 있으실 겁니다.
단순 연결 리스트의 구현에 앞서, 단순 연결 리스트는
데이터와 주소를 저장할 수 있는 '노드'를 사용합니다.
순차 자료구조는 단순히 데이터만 입력하면 되지만
연결 자료구조는 데이터를 입력 후,
자신의 위치를 뒤에 또는 앞에 노드와 이어주어야 합니다.
(화물 기차에 비유를 하자면 짐을 A화물칸에 다 실었는데, A를 그 이전, 앞의 화물칸이랑 연결하지 않고 그냥 A화물칸은 내버려둔 채 떠나는 느낌? - 추상적이네요,,)
typedef struct ListNode {
char data[10];
struct ListNode* link;
}listNode;(아니,, 저기서 구조체는 listNode이고, 나중에 코드 보니까 노드들은 listNode를 동적 할당하는데,,
왜 ListNode를 사용해요?) 저만 궁금한가요?
네?..
아직 구조체가 정의되어있지 않기 때문에, ListNode를 사용하는 것입니다.(TMI 죄송합니다.)
또한
여러 개의 노드가 이어져있는데, 이 중 가장 앞에 저장된 노드를 쉽게 찾기 위해
head라는 포인터 또한 새로 할당해야 합니다.
typedef struct {
listNode* head;
}linkedList_h;
linkedList_h* createLinkedList_h(void) {
linkedList_h* L;
L = (linkedList_h*)malloc(sizeof(linkedList_h));
L->head = NULL;
return L;linkedList_h(새로운 자료형)라는 구조체에는!
listNode *head; 한 개의 노드를 지목할 수 있는 head라는 포인터가 선언되어있습니다.
포인터는 초기화 또는 다른 변수로부터 할당받아야 사용이 가능해서!
linkedList_h *L=createLinkedList_h();
createLinkedList_h()라는 함수를 통해 동적 할당받은 1개의 노드를 얻습니다.
void insertFirstNode(linkedList_h* L, char* x) {
listNode* newNode; //새로운 노드 포인터를 선언 후,
newNode = (listNode*)malloc(sizeof(listNode)); // 동적할당받습니다.
strcpy(newNode->data, x); //이후 사용자로부터 받은 데이터x를 newNode에 복사합니다.
newNode->link = L->head; //L->head ==NULL, 노드가 가리키는 다음 link가 NULL을 뜻합니다.
L->head = newNode; // L->head는 newNode를 처음으로 연결합니다.
}
void insertMiddleNode(linkedList_h* L, listNode* pre, char* x) {
listNode* newNode;
newNode = (listNode*)malloc(sizeof(listNode));
strcpy(newNode->data, x);
if (L == NULL) { //노드가 없을 경우
newNode->link = NULL; //insertFirstNode()의 역활
L->head = newNode;
}
else if (pre == NULL) //노드가 한개일 경우,
L->head = newNode;
else {
newNode->link = pre->link; //노드가 여러개 연결되어있을 경우, 데이터 삽입을 원하고자하는 위치 이전 노드가 가리키는 다음노드를연결후
pre->link = newNode; //이전노드에 x데이터가 들어있는 노드를 삽입합니다.
}
}
insertLastNode(linkedList_h* L, char* x) {
listNode* newNode; //데이터 x 를 저장할 노드
listNode* temp; //마지막의 노드를 찾기위한 temp노드포인터
newNode = (listNode*)malloc(sizeof(listNode));
strcpy(newNode->data, x);
newNode->link = NULL;
if (L->head == NULL) {
L->head = newNode;
return;
}
temp = L->head; // temp 포인터를 새로 할당한 이유는, L->head로 직접 찾을 경우 L->head는 결국 첫번째원소를 영영찾을수 없게 되기 때문입니다.
while(temp->link != NULL) //L->head에서 연결되어있는 마지막 노드까지!수행 후
temp = temp->link; //다음 노드 지목!
temp->link = newNode; //그마지막노드에 x데이터가 들어있는 newNode를 삽입합니다.
}맨 처음 공부했을 때
insertFirstNode() 함수에서 맨 마지막에 있는 L->head=newNode가 이해가 안 갔었는데,
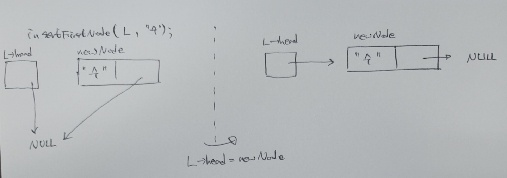
좌측 L->head=newNode수행 이전,
우측 == 수행 이후
저 코드가 있어야 head와 newNode를 연결할 수 있다는 것을 알게 되었습니다.
그럼 이미 insertFirstNode(L, "수");
이후에 insertFirstNode(L, "월"); 을 하게 된다면??
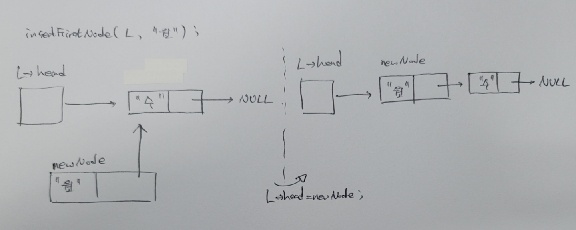
새로운 노드 newNode는 데이터 "월"을 저장하고, L->head가 지목하고 있는 첫 번째 노드인 "수"노드를 newNode 또한 지목 후,
L->head=newNode연산을 거쳐
총 2개의 데이터가 연결됩니다.
insetFirstNode의 사용 원리를 그림으로 이해하면
insertMiddleNode, insertLastNode의 사용방법 또한 쉽다는 것을 알 수 있습니다.
Q> insertMiddleNode에서 삽입하고자 하는 특정 위치에서 그 이전에 연결된 노드 listNode *pre는 어떻게 찾나요?
그 방법은 insertLastNode를 이해하시면 아주 간단합니다.
insertLastNode에서 listNode *temp포인터가 어떻게 마지막의 노드를 찾는가? 와 유사하게
while문에서 노드가 갖고 있는 데이터와 pre노드가 갖고있는 data를 비교해서 같을 경우에
그 listNode를 반환하면 됩니다.
listNode* searchNode(linkedList_h* L, char* x) {
listNode* temp;
temp = L->head;
while(temp != NULL) {
if (strcmp(temp->data, x) == 0) //만약 중간에 연결리스트에서 노드->데이터와 x가 같을경우
return temp;
else
temp = temp->link; //해당노드가아니면 다음노드로 치환.
}
return temp; //맨마지막의 노드일 경우,
}insert First, Middle, Last와 insertLastNode, searchNode 간에
코드들이 상당히 유사하다는 것을 알 수 있습니다.
원형 연결 리스트일 경우 마지막의 노드를 searchNode 한 후,
그 노드를 L->head가 가리키고 있는 첫 번째 노드를 지목하면 원형 연결 리스트가 되는 것입니다.
말로 이해하면 어렵습니다.
(교수님 : "그림을 통해서 이해하세요!!)
정말입니다 :).
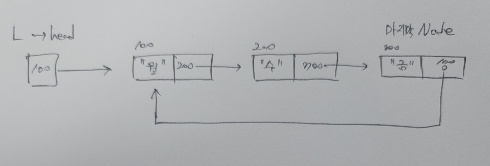
원형 연결 리스트의 경우에는 노드의 link는 절대 NULL을 지목하지 않습니다.
노드가 한 개일 경우 그 노드는 자신의 주소를 가리키기 때문입니다.
위의 예시는 단순히 한 개의 데이터를 저장하는 방법이었지만,
상황에 따라서 순차 자료구조의 응용 예인 희소 다항식(ex x^1000+4*x^3+1)
에서 지수와 계수를 두 개의 데이터로 갖는 구조체를 선언하는 방식으로 구현할 수 있습니다.
대부분의 순차 자료구조를 연결 자료구조로 구현할 수 있습니다. (노동이 필요할 뿐...)
탐색이 느린
연결 자료구조를 사용하는 경우는
자료의 삽입과, 삭제가 많은 경우에 주로 사용됩니다.
삽입과 삭제가 위치하는 A노드의 이전 노드만 찾아서,
A노드의 다음 노드에 이전 노드를 연결시키면 되기 때문입니다.
Q> 단순 연결 리스트와 원형 연결 리스트의 차이점이 무엇인가요?
가장 큰 차이점은 일단 단순 연결 리스트는 마지막 노드가 존재하지 않다는 것입니다.
또한 원형 연결 리스트의 경우에는 NULL을 지목하는 link가 존재하지 않습니다.

이상입니다.
'ComputerScience > Algorithm concepts' 카테고리의 다른 글
| [C언어/자료구조] Stack. 스택의 의미와 필수 함수, 응용 (0) | 2021.09.16 |
|---|---|
| [자료구조] 중위표기식과 후위표기식 간 변환방법 완벽하게 부수기 +_+ | stack의 응용 (2) | 2021.09.16 |
| [C언어] 2차원, 3차원 배열을 통한 순차 자료구조의 사용 예시(테트리스 블록, 휴대폰 판매량, 선형 list) (0) | 2021.08.28 |
| [C언어]알고리즘 (Time Complexity)시간 복잡도와 빅오 표기법 (0) | 2021.08.24 |



