그래프란 무엇인가?
일반적으로 그래프 하면 떠오르는 개념은 통계 수치를 비교할 때 사용되는 히스토그램(histogram), 방정식 같은 이미지를 떠올린다. 알고리즘에서 그래프는 어떤 현상, 사물을 정점으로 표현하고 연관된 정보를 간선을 통해 표현한다. 이 또한 그래프의 개념에 속한다. 다시 말해 정점은 주요한 대상 정보를 나타내고 간선은 정점과 정점(정보와 정보)을(를) 이어주는 관계가 된다.
즉, 데이터가 존재할 때 각 데이터를 연관 지어 시각적으로 표현한 것을 그래프라고 한다.

위 그림은 네트워크와 연관된 이미지이다. 위에서 흰색 점들은 선으로 연결되어있다. 이는 그래프로 간주된다.

친분 관계 또한 그래프로 나타낼 수 있다.
그래프를 표현하기 위한 개념
그림2를 보면 사람들이 연결되어 있다. 이를 통해 친분 관계를 쉽게 알 수 있다. 단순히 선으로 관계를 표현하지 않고 얼마나 친한지 선에 가중치를 추가함으로 친밀도 또한 파악할 수 있다. 어떤 한 사람만 다른 사람을 알 경우가 있다. 이 경우 간선에 방향을 통한 그래프로 표현이 가능하다.
그림2를 그래프로 표현하기 위해선 그래프에 대한 개념을 알아야 한다.
- 정점(Vertex) : 대상, 객체를 나타낸다. 그림2의 경우 사람이 해당된다.
- 간선(Edge) : 정점과 정점을 연결짓는 선이다. 그림 2의 경우 두 사람 간 간선이 없을 경우 모르는 사이라는 것을 알 수 있다.
- 무향 그래프: 그림1, 2와 같이 그래프의 간선에 방향이 없는 그래프임을 뜻한다.
- 유향 그래프: 그래프의 간선에 방향이 존재한다 // 이때 방향의 경우 일방통행 일 수도 있고 양쪽 다 오갈 수 있는 왕복 2차로 일 수 있다.
- G = (Vertex, Edge) // 그래프는 정점과 간선으로 이루어진다.
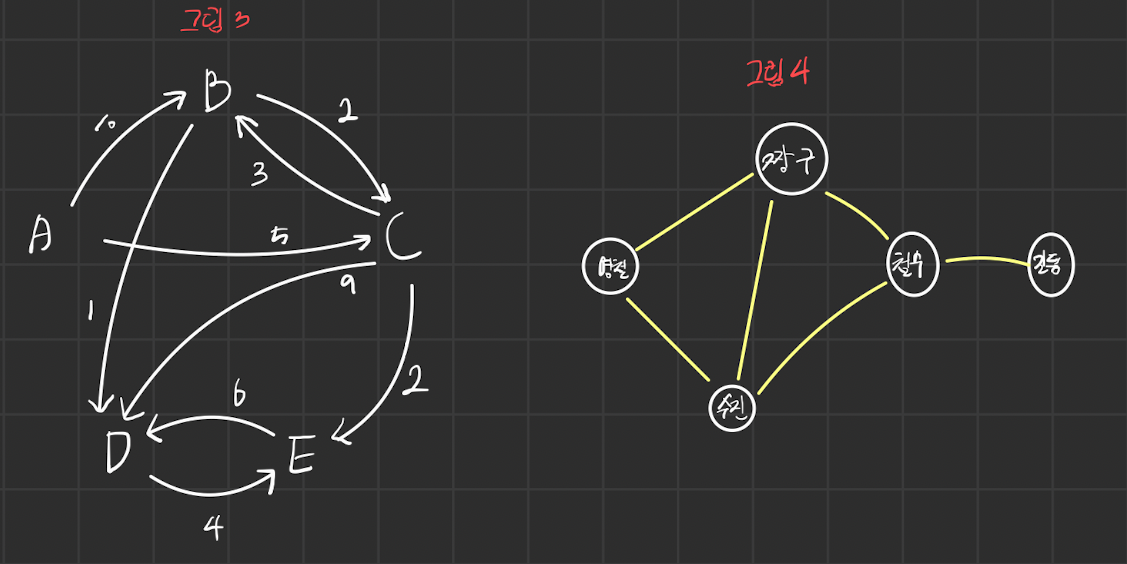
그림 3의 경우 간선이 방향을 띄고 있다. 유향 그래프이다. 또한 가중치도 존재한다.
그림 4의 경우 간선이 방향이 없다. 무향 그래프이다.
알고리즘에서 사용되는 그래프 또한 마인드맵, 여러 관계를 표현한 정보 등 다양한 실생활에서 볼 수 있는 친숙한 그래프이다.
그래프 표현 방법
그림 4의 친분 그래프를 예로 들자면
주어진 데이터에 대해서 단순한 그래프로 종이에 표현하는 방법은 정말 쉽다. 그냥 그리면 된다. 하지만 DFS, BFS Algorithm을 적용해 그래프를 탐색하기 위해서는 "컴퓨터"의 관점에서 컴퓨터의 언어로 그래프를 표현해야 한다.
그래프 표현방법 또한 다양한데
- 인접 행렬(배열)을 이용한 방법
- 인접 리스트를 이용한 방법
크게 이 두 가지로 나눌 수 있다. 상황에 따라 인접 리스트의 Type가 정보, 다음 정점, 가중치 등 다양하게 구현될 수 있다. 이외에도 딕셔너리, Map class(java) 등으로 정점과 간선의 정보를 표현할 수 있다.
그래프를 표현하면 그만인가?
그래프의 정점들 중에서 특정한 정점을 찾고 싶은 경우가 있다. 종이에 그래프를 그렸다면 사람의 경우 한눈에 파악이 가능하다. 하지만 컴퓨터의 경우 종이에 그린 그림을 데이터화 시켜 정점과 간선의 정보만 쏙 빼서 자료화할 수 없을뿐더러 자료화했다면 특정한 정보를 찾기 힘들 것이다. 개발자가 그래프에서 특정한 정보를 찾는 방법을 정의해야 한다.
특정한 정보가 담긴 정점은 어떻게 찾을 수 있을까? 모든 정점을 검색한다면 그중에서 원하는 정보를 찾을 수 있다! 근데 여러 개의 정점을 동시에 훑어가지는 못한다. 하지만 연산 처리 속도가 정말 빠르기 때문에 한 정점씩 정보를 훑어가지만 생각보다 빠르다는 느낌이 들 수 있다. 하지만 다량의 데이터라면 컴퓨터는 한 개씩 훑어가기 때문에, 정점과 연결된 정점들 중에서 특정 정보를 찾는 방법을 효율적으로 다루는 방법에 대해 생각해야 한다. 또한 이미 검색한 정점을 또 검색하지 않는 방법도 생각하면서 코드를 구현해야 한다.
그래프의 정점을 탐색하기 위한 대표적인 방법이 있다. DFS, BFS 탐색 알고리즘이다. 이 두 알고리즘은 그래프에서 정말 핵심적인 탐색 방법이다. 방법은 매우 간단하다.
DepthFirstSeatch. DFS란?

그림 5에서 모든 정점을 탐색하기 위한 방법으로 DFS를 우선 소개한다.
DeepFirstSearch 알고리즘 이름에 걸맞게 탐색한 정점을 기준으로 아직 탐색하지 않은 정점이 있을 경우 해당 정점을 탐색하고, 또 방문한 정점을 기준으로 아직 탐색하지 않은 정점이 존재할 경우 해당 정점을 탐색해가는 알고리즘이다.
탐색하기 전에 제일 처음 탐색해야 할 시작 정점이 주어져야 한다. 그래프의 특성상 어디가 루트 노드인지 정해져 있는 트리가 아니기 때문이다. 그래프의 한 범주로 트리가 포함되어 있기 때문에 그림 5의 트리 그래프를 예로 DFS탐색을 할 것이다.
시작 정점을 1로 가정했을 때 DFS 탐색 진행 순서는

이렇게 화살표의 방향으로 DFS탐색이 진행된다(그림이 쫌..)
눈으로는 단번에 파악할 수 있다. 하지만 이를 코드로 구현하기 위해서는
- 그래프의 정보를 담을 수 있어야 한다.
- 스택을 사용해 아직 탐색할 정점이 남은 정점을 기록해야 한다. + stack의 top 원소를 기준으로 새로운 인접한 정점들을 탐색한다.
- 방문한 정점에 대해서는 방문 완료 처리를 해야 한다.
이 세 가지 개념이 필요하다.
간단하게 스택에 push 되고 pop 되는 순서를 표현하자면
- 시작 정점 1이 주어지면 스택에 push 한다.
- 시작 정점 1에서 아직 탐색하지 않은 정점 2개가 있다 이중에 정점 2를 우선 탐색하는데 아직 정점 3은 탐색하지 않았으므로 정점 1은 pop하지 않고 정점 4를 스택에 push 한다.
- 정점 2에서 아직 탐색해야 할 정점 두 개가 있음으로 정점 4부터 우선 탐색을 하는데 아직 정점 5를 탐색하지 않았으므로 정점 2는 pop하지 않고 정점 2를 스택에 push 한다.
- 정점 4에서 아직 탐색하지 않은 정점 8이 있기에 정점 8을 스택에 push 한다.
- 정점 8과 인접한 정점 중 아직 탐색하지 않은 정점이 없음으로 stack에서 pop 한다.
- 정점 4와 인접한 정점 중 아직 탐색하지 않은 정점이 없음으로 stack에서 pop 한다.
- 정점 2에서 아직 탐색하지 않은 정점 5가 존재함으로 정점 5를 stack에 push 한다.
- 정점 5와 인접한 정점 중 아직 탐색하지 않은 정점이 없음으로 stack에서 pop 한다.
- 정점 2에서 아직 탐색하지 않은 정점이 없음으로 stack에서 pop 한다.
... 의 과정이다. 언제까지? stack의 top 이 비어있기 전까지
그림으로 시각화를 한다면

위와 같은 과정을 반복한다. 정점들이 들어갔다가 나오면서 연결된 다른 정점들을 탐색하고 특정한 조건이 없다면 결국엔 정점 1에서 연결된 모든 정점을 탐색할 것이다.
여기서 주의해야 할 점이 있는데 stack에 pop 된 정점을 다시 stack에 push 해서 탐색하는 무한 탐색의 과정이 일어날 수 있다. 따라서 이를 해결하기 위해서는 방문 처리를 해주어야 한다.
스택에 삽입된다는 의미는 해당 정점에 대해 탐색을 했다는 의미이다. 그래서 stack에 추가 후 해당 정점을 방문 체크 완료를 한다면 pop 됐을 때 그 정점이 다시 stack에 push 되는 경우는 없을 것이다.
BreadthFirstSearch. BFS란?
DFS는 이미 방문한 정점에 대해 아직 방문해야 할 두 정점이 있다면 pop하지 않고 그중 하나 push해서 계속 탐색해 나간다. (어우 답답해 한 정점을 탐색했을 때 인접한 두 정점이 둘 다 탐색하지 않았다면 그 둘을 체크하면 안 돼?) 이 방법이 바로 BFS 알고리즘이다.
BFS는 DFS와 다르게 큐를 이용해서 그래프에 인접한 정점들을 탐색해 나간다.
그림 5를 BFS로 탐색을 한다면 아래 그림과 같이 표현된다.

어떤 정점에 대해서 연결된 정점들 중 탐색하지 않은 정점들이 존재한다면 해당 정점 들을 전부 탐색한다. 그리고 새로 탐색한 첫 정점부터 마지막 정점까지 우선 첫 정점부터 시작해 연결된 정점 중 탐색하지 않은 정점이 존재한다면 해당 전점들을 전부 탐색의 반복이 BFS의 주요 알고리즘이다.
BFS 또한 코드로 구현하기 위해서는 아래와 같은 지식이 필요하다.
- 큐에는 탐색해야 할 정점이 들어간다.
- rear index를 증가시키면서 (rear) pop 된 정점을 기준으로 인접한 정점들을 큐에 넣는 방식(Front index 증가)으로 탐색이 진행된다.
- 이때 큐에 들어온 정점은 탐색이 완료된 정점이다. ( 왜 탐색이 완료된 정점을 넣을까? -> 인접한 정점 중 탐색하지 않은 정점이 있을 수 있기 때문)
- 큐에 들어온 정점은 방문 체크를 통해 무한 순환 탐색 오류 방지를 사전에 막는다.
큐의 상태를 시각화한다면 한층 이해하기 쉬울 것이다.

무엇보다 중요한 것은 큐에 삽입될 때 방문 처리를 하는 것이다. 방문 체크를 하지 않는다면 추후 그래프에 인접한 정점에 대해 탐색할 때 이미 탐색한 정점이 다시 방문될 수 있기 때문이다.
DFS와 BFS 차이
일반적으로 특정한 정점을 빠른 시간 내에 더 적은 호출로 찾는 경우는 BFS이다. 그럼에도 DFS와 BFS 둘 다 최악의 경우 모든 정점들을 완전 탐색을 한다. 인접 행렬을 통해 그래프를 구현했다면 최악의 경우 O(n^2)이고 인접 행렬( 동적 배열 크기)로 그래프를 구현했다면 최악의 경우는 O(n+e)이다. 탐색한 정점에 대해 저장하는 방법 또한 DFS == stack, BFS == queue이므로 다르다는 것을 알 수 있다.
'ComputerScience > Algorithm concepts' 카테고리의 다른 글
| [Algorithm] 플로이드 와셜(Floyd-Warshall) 개념 뿌수기!! (0) | 2023.01.10 |
|---|---|
| [Swift/Algorithm] 우선순위 큐 개념 정리, 최소 힙 개념 with 라이노님 Heap 코드 리뷰 (2) | 2023.01.06 |
| [알고리즘]다익스트라 최단 경로 알고리즘 개념 부수기 / heap이 뭐야? (0) | 2022.08.27 |
| [알고리즘] LIS 최장 증가 부분 수열 파해치기!! with Swift (0) | 2022.08.09 |



